Research
Our research explores core challenges in computer vision, multimodal artificial intelligence, and embodied intelligence, with a strong emphasis on building intelligent systems that perceive, reason, and act in the real world. This page introduces our major research directions and representative topics, spanning from fundamental algorithmic advances to system-level integration for practical and scalable AI solutions.
Generative AI
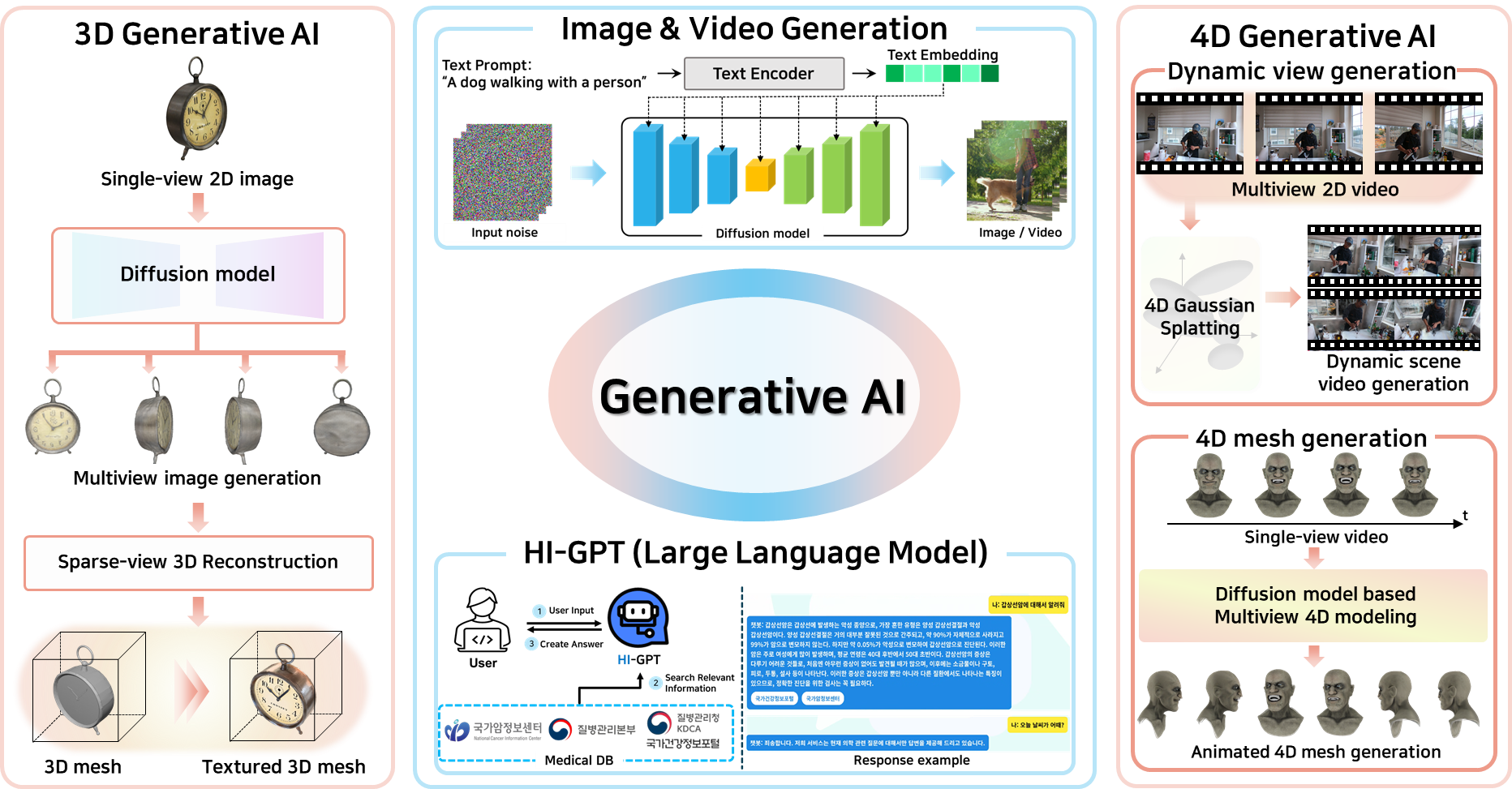
We study modern generative models including diffusion models, GAN variants, and recent video and 3D/4D generative frameworks. Our research emphasizes controllable generation, temporal and spatial consistency, efficient inference, and safety. We aim to build practical generative pipelines that can reliably produce high-quality images, videos, and 3D/4D representations under real-world computational and deployment constraints.
Embodied AI & Robotics
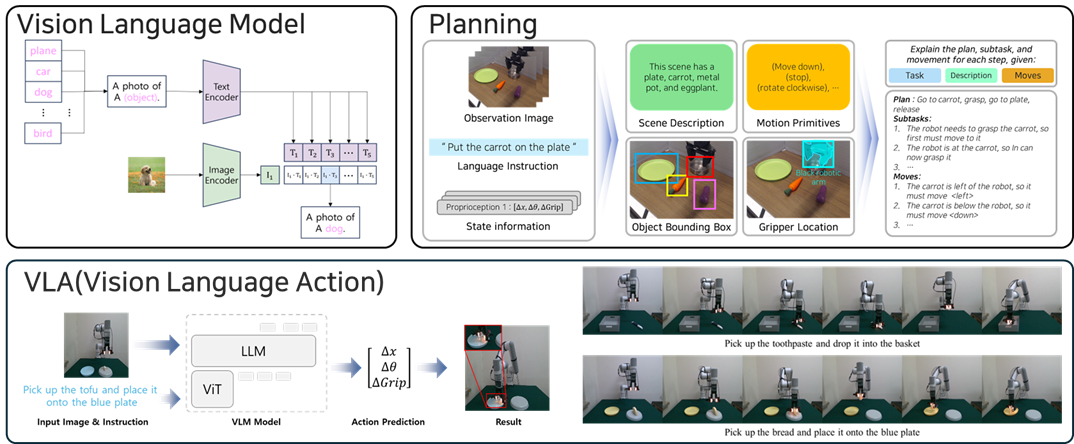
Our embodied AI research bridges perception and action through planning, control, and interactive decision-making in physical environments. We investigate data-efficient learning methods for robotic manipulation and embodied interaction, focusing on how agents can acquire skills from limited data and adapt to new situations. Our goal is to build robust embodied agents that tightly integrate perception, reasoning, and action, enabling reliable operation in complex and unstructured real-world settings.
Vision & Multimodal Learning
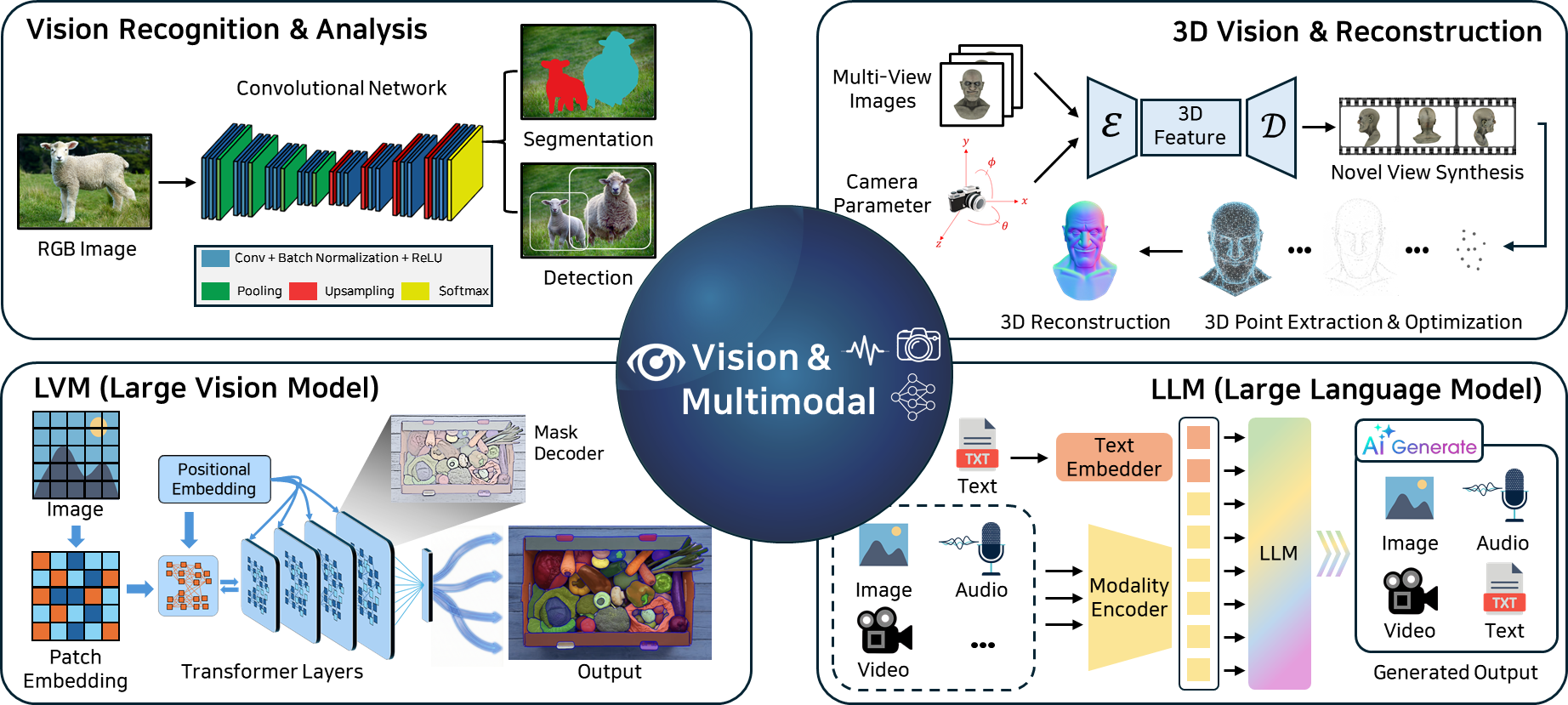
We develop robust visual representations and multimodal learning methods that combine visual, linguistic, and structured information. Our research covers vision–language models (VLMs), fine-grained recognition, and reliable perception under distribution shifts and challenging conditions. We also study training strategies and model architectures that improve generalization, robustness, and interpretability across diverse real-world environments.
Selected Keywords
Diffusion Model, 3D/4D Generation, Vision-Language-Action (VLA), Multimodal Foundation Models, Embodied Agents, Robotic Manipulation, Data-Efficient & Trustworthy AI